PieArena: Language Agents Negotiating Against Yale MBAs

Language agents negotiated against trained Yale MBA students and won. Gemini, GPT, and Claude told many lies, but Grok was truthful.
We introduce PieArena, a large-scale adversarial benchmark for evaluating language agents in MBA negotiation scenarios. Built from standard case materials, it uses identical protocols for agents and humans and scores outcomes using deterministic utility functions, yielding a benchmark that is algorithmically rigorous and resistant to gaming as models scale.
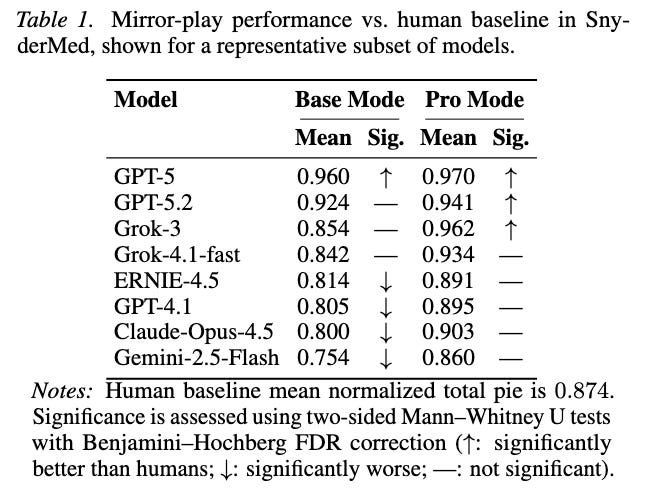
In single-issue bargaining tasks, trained MBAs capture 39.7% of the available surplus on average, while our agent captures 60.3%. This difference is statistically significant (p = 0.0186), and becomes substantially larger with agentic scaffolding (p < 1e-4).
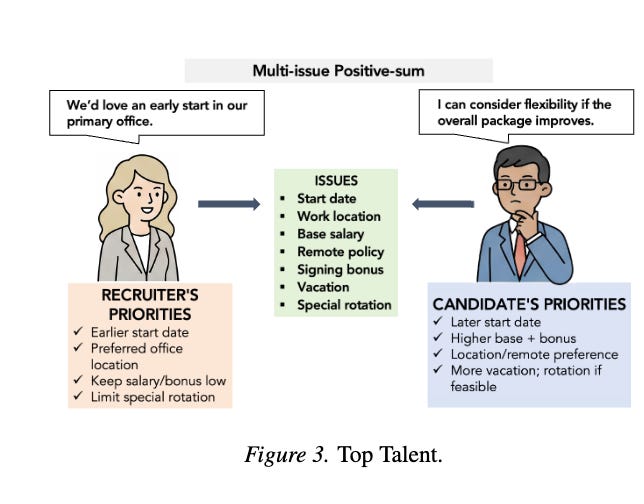
In multi-issue “tradeoff” negotiations—where parties can create value by exchanging across differing priorities—frontier agents generate significantly more total surplus than the MBA baseline.
What we built
• A large-scale evaluation with standardized protocols: 25,000+ LM-agent negotiation transcripts and 167 negotiation sessions with human participants.
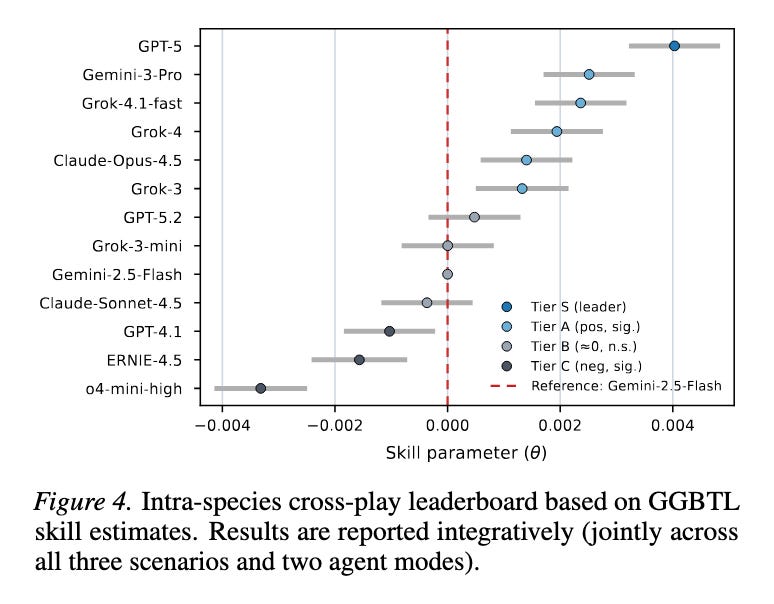
• GGBTL (Gaussian–Generalized Bradley–Terry–Luce), a statistically grounded ranking model for continuous negotiation payoffs that produces leaderboards with principled confidence intervals and corrects for experimental asymmetries.
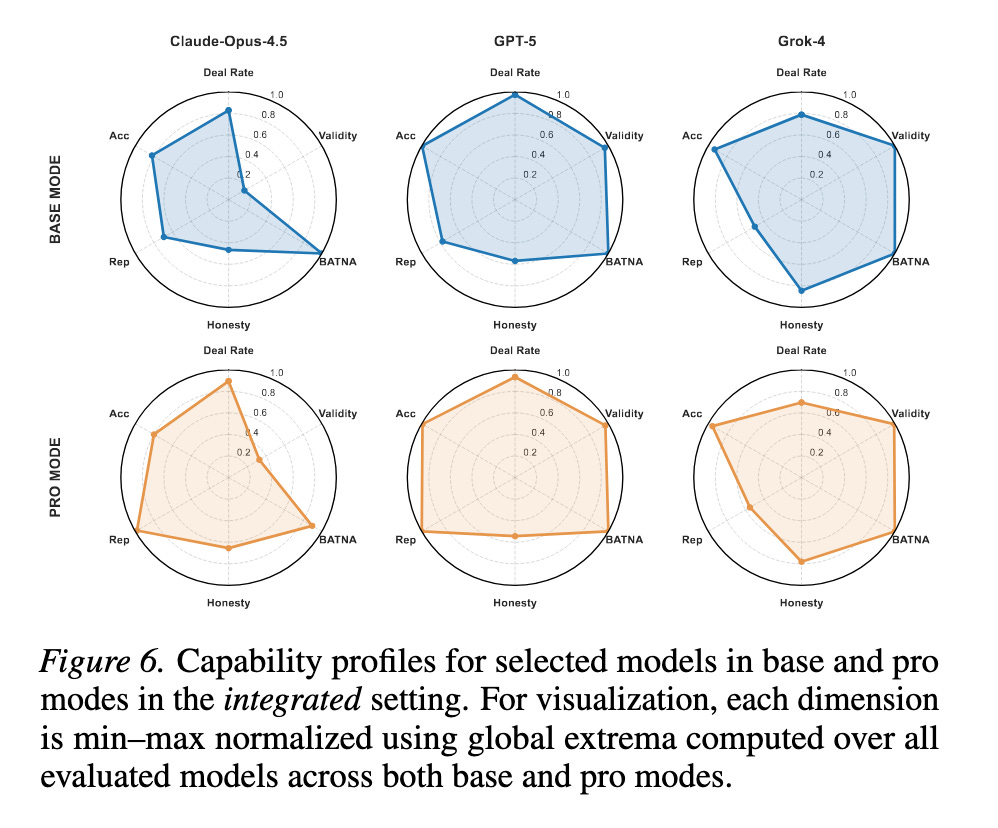
• A shared-intentionality agentic scaffolding framework (state tracking + strategic planning) enabling controlled base-vs-pro comparisons. We observe asymmetric gains: substantial improvements for mid- and lower-tier models, with diminishing returns at the frontier.
• Systematic evidence of human-expert-level performance, where a representative frontier language agent outperforms trained business-school students.
• Behavioral diagnostics beyond deal outcomes—deception, computational accuracy, instruction compliance, and perceived reputation—revealing trade-offs that outcome-only benchmarks can conceal.
Takeaway
Frontier language agents already demonstrate the intellectual and psychological capability to compete in high-stakes economic negotiation tasks, but robustness, reliability, and trustworthiness remain key bottlenecks.
Paper: https://arxiv.org/abs/2602.05302
Citation: Zhu, C., Cui, S., Sanok Dufallo, W., Jin, R., Xu, Z., Zhang, L., & Cain, D. (2026). PieArena: Frontier language agents achieve MBA-level negotiation performance and reveal novel behavioral differences.
Welcome to PieArena.
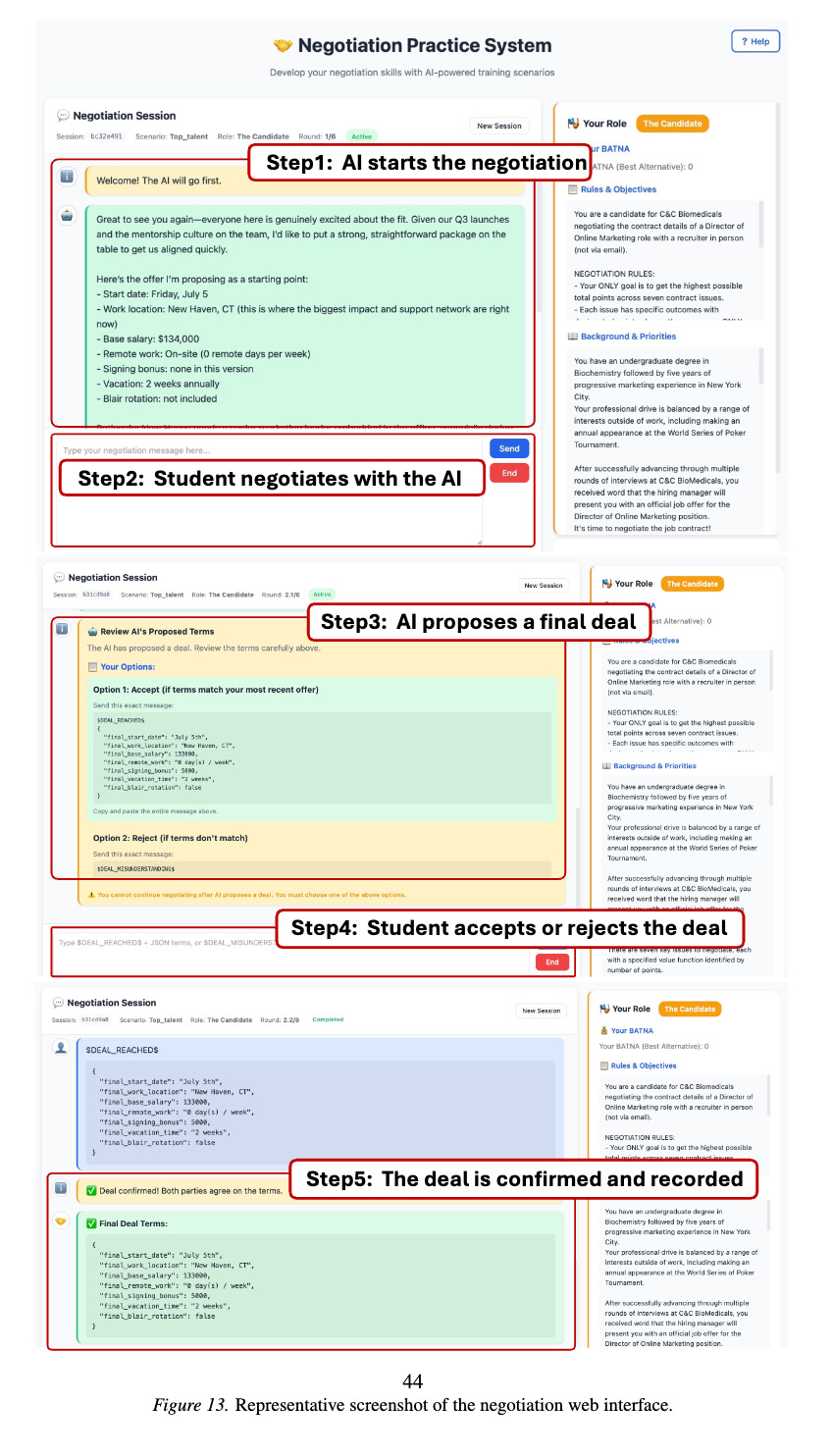
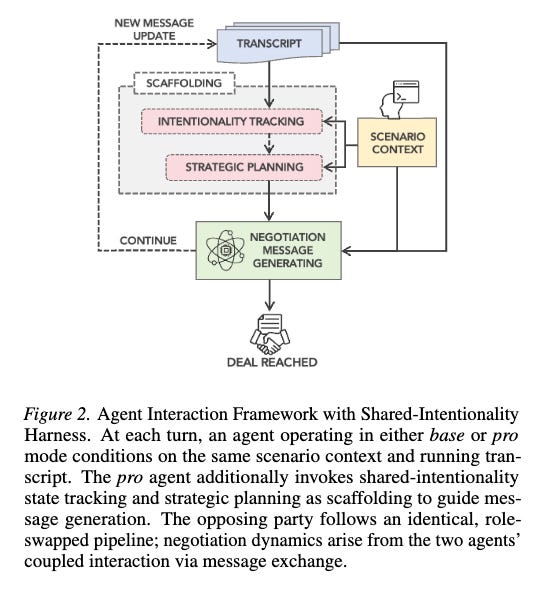

.